思路起源
最近碰巧需要研究使用LLM来处理一些数据,从一个研究AI4Network的哥们口中得知了一种用LLM做网络异常诊断的方法。该方法的核心思想是把大语言模型当做一个强大的序列处理工具,任由其对序列数据提取特征并做异常分类,简易流程图就像这样
graph TD; met1[吞吐量] met2[带宽] metdot[...] met3[时延] encode(编码) met1 ---> encode met2 ---> encode metdot ---> encode met3 ---> encode tokens[token] encode --> tokens
graph TD; tokens[token] embeddings[embeddings] tokens --embedding--> embeddings q[Q] k[K] v[V] embeddings --Wq--> q embeddings --Wk--> k embeddings --Wv--> v qs[q+PE] ks[k+PE] q --PosEmb--> qs k --PosEmb--> ks qk(MatMul) qs --> qk ks --> qk weight[Weight] qk --norm & Softmax--> weight wv(MatMul) v -------> wv weight -->wv wv --fc classification--> output output
简单来说主要是两部分:
- 先将网络当中的各种指标整理成向量,每一个截面能收集一个向量,所以在时间轴上是一个矩阵,可以取过去一段时间的所有截面来作为输入。那第一步就是将这个向量编码成一个固定的格式,方便后续与模型对齐。
- 将编码后的token转成选用的语言模型使用的embedding维度(对齐)
- 将对齐后的向量输入LLM(此处我简要化成了一个SelfAttn块,因为这是本文要讨论的重点)
- 输出经过一个全连阶层得到几大异常分类,计算标签和预测值之间的交叉熵,最优化似然值的相反数来调整embedding、推理模型、fc分类器三个部分
由于我不是做网络的,上述方案的可行性和有效性不属于我讨论的范畴,但是受此启发,我对QKV查询机制展开了一些联想,并与朋友们展开了一轮激烈的讨论
QKV:哪里来的怪东西
以下的逻辑链条属于我自己的想法,可能与现实有所出入。
KV?查表
| 身高 | 体重 |
|---|---|
| 150 | 48 |
| 160 | 55 |
| 170 | 65 |
| … | … |
| 190 | 80 |
假设我有这么一张KV表(K是身高V是体重),我想知道一个身高为165的人体重大概是多少,应该如何在表中查?
插值(interpolation)
165落在[160, 170]这个区间里,那么我们可以根据160和170对应的体重来估计165对应的体重。那么最简单也是最直观的想法就是,我们假设160到170之间的体重是随身高线性变化的,那么165就是160和170体重的平均值,也就是所谓的线性插值。或者我们考虑体重的变化是一条抛物线(两个可以求解出无数条抛物线,任选一条都能取出一个预测的体重值来),等等。
插值的方法很直观,但是他有一个弊端就是,任由我们有一张超大的KV表,有这么多全局的信息,却只取了两个点,有点太浪费了
那有没有一种更好的方法,能够利用KV表的所有信息呢?
回归(regression)
基于先验信息(就是这一张表),我们可以挑选一个映射f,这个f负责把身高映射到体重:
最简单的就是线性回归了,即$y=ax+b+\epsilon$,其中:
这玩意怎么来的非常简单,主要就是最小二乘$\mathop{min}\limits_{a,b}\sum(\hat{y_i}-y_i)^2$,都是高中数学的部分我就不细说了。
除了线性回归也可以根据KV的具体分布,来对K或者V做指数或者对数,然后再做线性回归,这也就是所谓的指数回归和对数回归
回归过于关注全局的信息,往往会忽略局部的信息,比如Q于某几个K距离很近,那我们其实更希望这几个K对应的权重更大一些,有没有一种方法可以实现这一权重分配呢?
距离加权平均值
我们能不能为所有的KV对都分配一个权重,然后对他们取加权平均呢?答案是肯定的,但是这也面临一个新的问题,权重该如何分配?
距离定义
首先我们定义距离,用$L(q, k_i)$表示q和$k_i$之间的距离。对于这个身高来说,距离本身是有方向的比别人高五厘米和比别人矮五厘米是不同的。考虑到我们希望用身高对应的key来预测q对应的体重,那么160和170对于165来说都是同等重要的(即距离应该是无向的)。
$L$就可以是$|q - k_i|$,$|q - k_i| ^2$,两者的区别在于,前者在$q = k_i$时不可导,后者定义域内可导,这都是后面再考虑的问题了。
权重分配
有了距离$L$,我们应该如何分配权重呢。不需要动脑就可以想到,诶,我可以用相反数或者导数啊
或者
而这两个都各自有着很大的问题,那就是当$q=k_i$时的数值问题,前者在$q$刚好与$k_i$匹配的时候,分配给$k_i$的权重是0,那加权平均的时候就会跳过这一个kv对。而后者在这个点上行为未定义(1/0),也不合适。虽然对于科学计算而言1/0会给你返回一个infinity,对应一个浮点数,那么计算加权平均的时候就会是inf/inf,查询的结果就是这个匹配的kv对,但是这本身是不合理的。
这里大家常用的方法其实是
可以看到在指数函数很好的处理了这一个点的值的问题,而e指数还有一大特点就是他的导数也是他自身(这里也不太重要)
那我们就定义权重分配的函数
归一化
这样的分配权重解决了数值范围的问题,将所有权重都分配到(0,1]之间了。不过这种方法分配的权重大小完全取决于距离函数的输出,导致距离较小的k权重比距离大的权重要大很多,使得某些v对预测的贡献量远大于其他,结果不够平滑,可以根据具体的应用场景选择使用归一化操作。如果你希望每个k对应的v都能有一定的贡献,就归一化;如果你希望直接依赖于距离的差异并对局部相似的k赋予较大权重,可以不归一化。
归一化的方法有很多,比如使用Softmax方法将权重转化为概率分布,所有权重的和为1,能够有效对比不同k的影响力。
另外,使用Softmax可以确保权重总和为1,且更好地分配权重,特别是当k、q的分布较为复杂时,可以防止极端值对结果的过度影响。
查KV表的推广
多行查询
一次除了可以查一个身高体重,实际上也可以查多个身高对应的体重,也就是说
Q的每一行都代表一次查询,假设有t条查询,有h个kv对,我们可以把Q扩展到$Q^*\in R^{t,h}$那么Q和K的距离就是
得到一个t行h列的距离矩阵W,$W_{i,j}$表示$Q_i$和$K_j$的距离
那$Softmax(W, axis=1)*V$就能得到一个t行1列的值,每一个值就代表$Q_i$对应的查询结果。
$Q_i$和$Q_j$之间的关系
在查询的时候,不难发现$Q_i$和$Q_j$其实是相互独立的,对于身高的查询来说,这无可厚非,因为不同的查询,查询的位置都不应该影响查询的结果。但是如果我们换个场景,我们需要处理文本序列的情绪分类,那么下面两个句子只是两个词的位置调换一下,情感分类结果其实是大不相同的:
- I eat apple
- Apple eats I
如果只用前面提到的方法,那么三个词query到的值只是位置变换了,而值本身没有区别。那么按照前文的多值query的方法显然就是不行了,因为我们引入了查询Q的序的概念,在查询的过程中除了需要处理每个query本身的值,还需要考虑每个query的位置。描述每个query所在的位置,这就是位置编码(Position Embedding)。
位置编码(PE:Position Embedding)
那对于一个Q来说,假设他是t行1列的查询向量,那位置编码其实就是对着t个位置进行一个编码,把每个位置的编码填入这么一个t行1列的表中,得到与Q形状相同的一个位置向量。
Transformer中通过简单的相加来让Q和K携带上位置信息:
这个想法很好理解,如果不加上位置编码,那么I eat Apple和Apple eats I就是简单的两行互换,没什么区别。而加上了位置编码,这两个句子就完全不同了,因为两个顺序下,Apple所加上的位置编码不同,所以两个句子中apple对应的值也不同。在数据层面体现出了两个句子的不同,剩下的就交给梯度下降就行了。
那对位置进行编码该如何设计,又有什么需要考虑的呢?以下两点是根本:
- 需要保证元素之间的相对距离关系,比如$Q_1$和$Q_3$之间的距离比$Q_1$和$Q_2$的远
- 要尽可能避免不同位置之间的编码重复。 如果在某两行他们的编码完全相同,或者说距离非常近就会出现词语对调后语意不变的问题。假设第i行和第j行位置编码重复了,那意味着一个句子把i和j行对应的词互换一下,互换前后两个句子加上位置信息的值也没有区别,即Apple eats I = I eat apple,这就乱套了。
线性位置编码
那为了解决上面这个问题,我们很容易想到,就用这个位置的下标作为编码,不就能解决这一问题了吗?
这也是最早期的设计方式之一,用下标作为编码,而这有个十分明显的问题,当你需要把这个位置编码加入到序列中时,因为位置编码本身是个无界的常数,如果直接与序列相加,过大的数值会干扰查询。
那越往后的位置,位置编码过大就会使得查询的权重构建方式异常的复杂。
解决这一现象也简单,我们让第一个元素为0,最后一个元素为1,中间就线性插值不就好了吗。
[0, 0.25, 0.5, 0.75, 1]
这也是比较合理的绝对位置编码方式,有效的控制了数值的范围,同时保留了距离的概念。
不过,由于Q的长度t是个变动的值,那对不同的t而言,每个位置的位置编码也是在变化的,那”I eat apple”和”I eat apple.”的位置编码就不同了(后者多了一个’.’,线性插值间隔就不一样了),而实际上他们的语意都是相同的,我们也不希望这两个句子在位置编码上不同。
那么有没有办法能让每个位置的值是个固定的值,且满足前面提到的要求呢?
二进制位置编码(Binary Position Encoding)
在查询的过程中,往往Q不是1维的向量,而是有t行d列的向量嵌入(embeddings)。比如身高查询的时候假设我们以0.1为粒度,范围定在[0,250],那么就能拆分出25011个点,每个查询值可以是一个one-hot向量。举个例子,查询172.5,对应向量1725索引处是1,其他位置是0的一个one hot向量。然后one hot空间太过稀疏,再用PCA或者Autoencoder等方法将大小为25011的空间压缩到一个自己需要的维度。
这里,假设我们查询压缩到两个维度,那么对于4条查询,可以仿照二进制编码,把每个位置都进行编码:
| Q | Emb1 | Emb2 |
|---|---|---|
| Q1 | 0 | 0 |
| Q2 | 0 | 1 |
| Q3 | 1 | 0 |
| Q4 | 1 | 1 |
要压缩到的空间(其实就是embedding空间)的密度可以自己更改,这里使用的是长度为2,理论上最长可以到25011,那就可以编码最长$2^{25011}$个位置,这是妥妥的够用的,每个位置填什么也就解决了。
虽然这样编码能给每个位置分配一个固定的值,但是他也带来了新的问题:
- 这样编码过于离散,只是能再高维四面体上取顶点0或1(这个是我从二维和三维图像中总结出来的,高维我也想象不出来)
- 对同一行而言,列与列之间太像了,容易遇上非常多个连续的0或1,导致神经网络很难找到这个空间的正交基(基向量之间相关性太强)
那下面我们将一步一步解决这两个问题。
正余弦位置编码
可以使用正弦函数来为每个位置的编码,从而利用[-1,1]这个实数域上的每一个点:
$PE_{t,d}$表示第t行第d列的位置编码,对应第$Q_t$和$Emb_d$。这样做可以解决第一个问题。此外,不同列之间的波长不同,波长不同正弦函数对t的敏感程度不同,也能帮助找到正交基。
到这里还没有结束,仔细观察这个函数,不难看出第i列的波长$\lambda=2^d\pi$。如果Embedding只是有两个维度,那两个维度对位置的编码是一个首尾相接的线,形状如下图。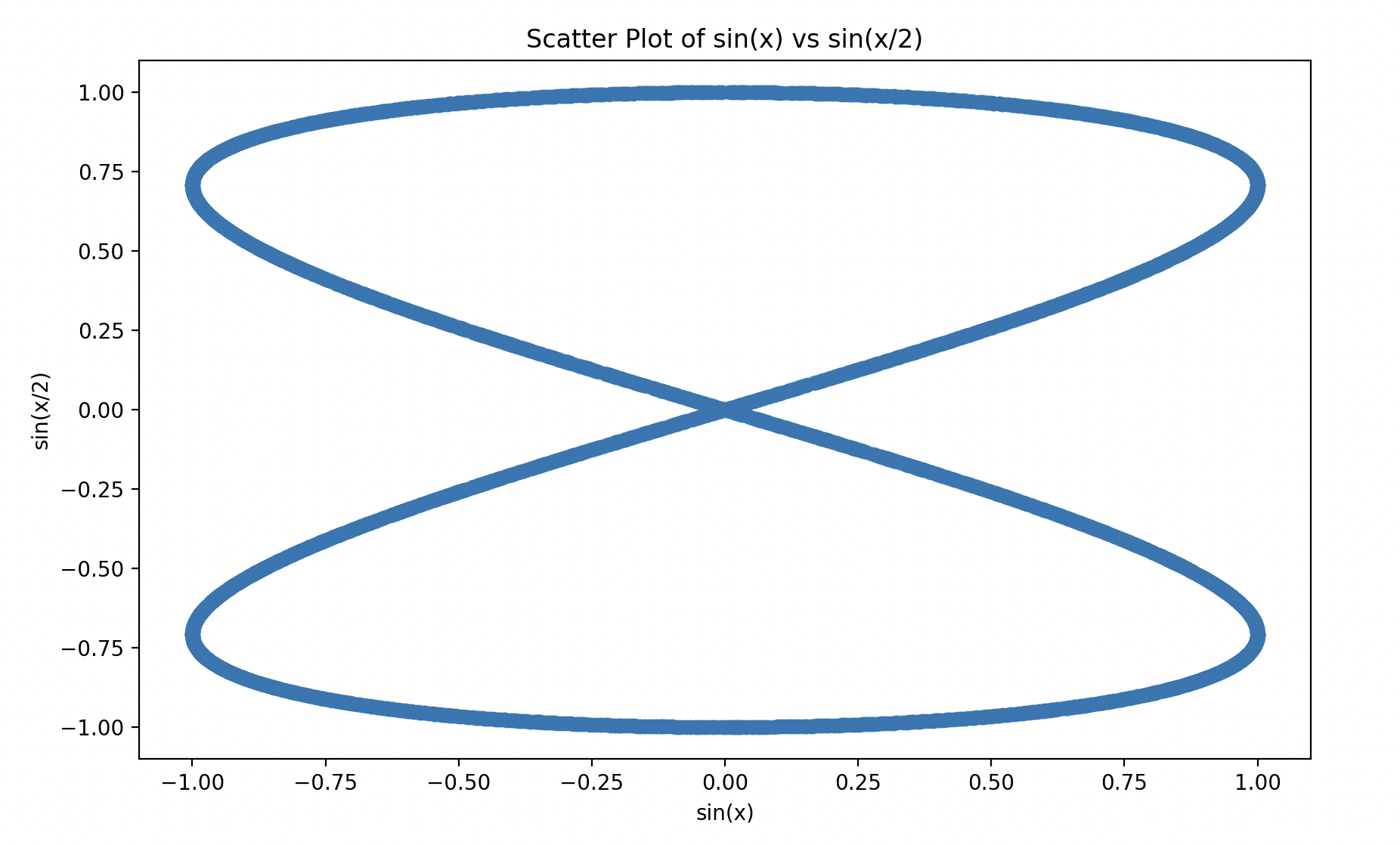
拓展到三维也是一样的封闭的环,这样的现象是因为正弦函数是周期性变化的。那就意味着,当Q的长度逐渐变大,就容易出现其中两行查询所对应的位置编码相同的情况,这显然不是我们希望看到的。
正余弦位置编码改进
那也就顺理成章的能够想到,既然是因为周期变化导致的,那我让它周期足够大不就行了。这个思路是对的,核心就是拉大波长来减少周期性的问题,可以通过下面两个方式:
- 让embedding的空间足够大,这样的话最大的d对应的波长$2^d\pi$就足够大,比如要应付最大长度1000的Q,那只需要$d \gt log(\frac{1000}{\pi}) \approx 5.763$就行了。
- 同样是拉大波长,我们使用$10000^d\pi$作为周长,这么长的波长,就不容易遇到两行完全相同的情况了
两个方案实际上都是可行的,对于前者,按照通义千问的embedding维度长度3584,如果使用前者,理论上它能够保证填$2^{3584}$数量级的query,不过模型什么时候能学到这一信息(收敛)也是有不同的,但是我不太懂这个方面的内容就不胡诌了。后者的话更甚之,在前者的基础上,同时把波长的底数从2变成10000,能够进一步改善周期性的问题(其实前者本身应该也是够用)
而这一编码方式,也是Attention is All You Need这篇文章所使用的,他只简短的用一小段提了一下,他使用的编码方式如下:
可以注意到,于我提到的编码方式不同的是,文章中还将相邻的两行偏移了$\frac{1}{4}$个波长(sin变cos)。这样做首先保证了两行(两个query)之间在值上的相邻,因为是同一个波函数的不同位置,且波长很长,两点相对接近。此外,它也让列于列之间有了显著的不同(对于相邻列sin和cos的相关性非常低,而每两列是同一个波长,i变化的时候波长也变了同时位移也变化了),降低了列之间的相关性。
而列于列之间的相关性低,能够让神经网络更好的分解这一空间并找到对应数量的相对正交的基向量,从而理解这一个位置编码空间,进而理解Q不同行之间的位置关系。
总结
本文主要从一次偶然的交流出发,探究了如何从一张KV表中查Q对应的值。在此基础上,推广了Q在多值情况下的做法,以及讨论了Q不同行之间的位置关系。然后探讨了如何“表示”位置,以及为什么Transformer的位置是用这么一个奇怪的公式表示的。